![]()
Portkey¶
Portkey 是一个全栈 LLMOps 平台,能够可靠、安全地将您的 Gen AI 应用程序投入生产。
Portkey 与 Llamaindex 集成的关键特性:¶

- 🚪 AI 网关:
- 🔬 可观测性:
- 日志记录:跟踪所有请求以便监控和调试。
- 请求追踪:了解每个请求的流程以便优化。
- 自定义标签:对请求进行分段和分类,以获得更好的洞察。
- 📝 通过用户反馈持续改进:
- 反馈收集:无缝收集对任何已处理请求的反馈,无论是生成级别还是对话级别。
- 加权反馈:通过为用户反馈值附加权重来获取更细致的信息。
- 反馈元数据:将自定义元数据与反馈相结合,以提供上下文,从而实现更丰富的洞察和分析。
- 🔑 安全密钥管理:
- 虚拟密钥:Portkey 将原始提供商密钥转换为虚拟密钥,确保您的主凭据不被触及。
- 多个标识符:能够为同一提供商添加多个密钥,或为同一密钥使用不同的名称,以便于识别,同时不损害安全性。
为了利用这些功能,让我们从设置开始
如果您在 colab 上打开此 Notebook,您可能需要安装 LlamaIndex 🦙。
%pip install llama-index-llms-portkey
!pip install llama-index
# Installing Llamaindex & Portkey SDK
!pip install -U llama_index
!pip install -U portkey-ai
# Importing necessary libraries and modules
from llama_index.llms.portkey import Portkey
from llama_index.core.llms import ChatMessage
import portkey as pk
您无需在 Llamaindex 应用程序中安装或导入任何其他 SDK。
步骤 1️⃣:获取您的 Portkey API Key 和 OpenAI、Anthropic 等的虚拟 Key¶
Portkey API Key:在此登录 Portkey,然后点击左上角的个人资料图标并点击“复制 API Key”。
import os
os.environ["PORTKEY_API_KEY"] = "PORTKEY_API_KEY"
- 导航到 Portkey 控制面板上的“虚拟密钥”页面,点击右上角的“添加密钥”按钮。
- 选择您的 AI 提供商(OpenAI、Anthropic、Cohere、HuggingFace 等),为您的密钥指定一个唯一的名称,如果需要,记下任何相关的用法说明。您的虚拟密钥就绪了!
 3. 现在复制并粘贴下面的密钥 - 您可以在 Portkey 生态系统内的任何地方使用它们,并确保您的原始密钥安全无虞。
3. 现在复制并粘贴下面的密钥 - 您可以在 Portkey 生态系统内的任何地方使用它们,并确保您的原始密钥安全无虞。
openai_virtual_key_a = ""
openai_virtual_key_b = ""
anthropic_virtual_key_a = ""
anthropic_virtual_key_b = ""
cohere_virtual_key_a = ""
cohere_virtual_key_b = ""
如果您不想使用 Portkey 的虚拟密钥,您也可以直接使用您的 AI 提供商密钥。
os.environ["OPENAI_API_KEY"] = ""
os.environ["ANTHROPIC_API_KEY"] = ""
步骤 2️⃣:配置 Portkey 功能¶
为了充分利用 Portkey 与 Llamaindex 集成的潜力,您可以配置上述各种功能。以下是 Portkey 所有功能及其预期值的指南
| 功能 | 配置 Key | 值(类型) | 必需 |
|---|---|---|---|
| API Key | api_key |
string |
✅ 必需(可外部设置) |
| 模式 | mode |
fallback, loadbalance, single |
✅ 必需 |
| 缓存类型 | cache_status |
simple, semantic |
❔ 可选 |
| 强制刷新缓存 | cache_force_refresh |
True, False |
❔ 可选 |
| 缓存有效期 | cache_age |
integer(秒) |
❔ 可选 |
| Trace ID | trace_id |
string |
❔ 可选 |
| 重试 | retry |
integer [0,5] |
❔ 可选 |
| 元数据 | metadata |
json object 更多信息 |
❔ 可选 |
| Base URL | base_url |
url |
❔ 可选 |
api_key和mode是必需值。- 您可以使用 Portkey 构造函数设置您的 Portkey API 密钥,也可以将其设置为环境变量。
- 有 3 种模式 - Single、Fallback、Loadbalance。
以下是如何设置其中一些功能的示例
portkey_client = Portkey(
mode="single",
)
# Since we have defined the Portkey API Key with os.environ, we do not need to set api_key again here
步骤 3️⃣:构建 LLM¶
通过 Portkey 集成,构建 LLM 变得简单。对所有提供商使用 LLMOptions 函数,使用与您在 OpenAI 或 Anthropic 构造函数中习惯使用的完全相同的键。唯一的新键是 weight,这对于负载均衡功能至关重要。
openai_llm = pk.LLMOptions(
provider="openai",
model="gpt-4",
virtual_key=openai_virtual_key_a,
)
上述代码说明了如何使用 LLMOptions 函数设置使用 OpenAI 提供商和 GPT-4 模型的 LLM。此函数也可用于其他提供商,从而使集成过程在各种提供商之间保持流畅和一致。
步骤 4️⃣:激活 Portkey 客户端¶
使用 LLMOptions 函数构建 LLM 后,下一步是用 Portkey 激活它。此步骤对于确保 LLM 可用所有 Portkey 功能至关重要。
portkey_client.add_llms(openai_llm)
就是这样!仅需 4 个步骤,您的 Llamaindex 应用程序就注入了先进的生产能力。
🔧 测试集成¶
让我们确保所有设置都正确。下面,我们创建一个简单的聊天场景,并通过我们的 Portkey 客户端查看响应。
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What can you do?"),
]
print("Testing Portkey Llamaindex integration:")
response = portkey_client.chat(messages)
print(response)
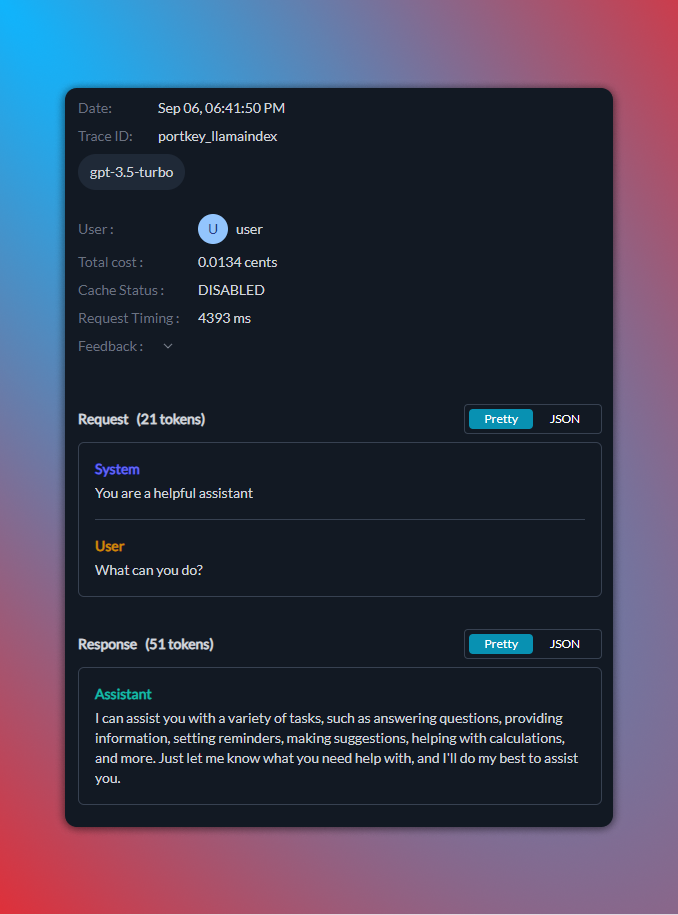
这是您的日志在 Portkey 控制面板上的显示方式
⏩ 流式响应¶
使用 Portkey,流式响应从未如此简单。Portkey 有 4 个响应函数
.complete(prompt).stream_complete(prompt).chat(messages).stream_chat(messages)
complete 函数需要字符串输入 (str),而 chat 函数使用 ChatMessage 对象数组。
使用示例
# Let's set up a prompt and then use the stream_complete function to obtain a streamed response.
prompt = "Why is the sky blue?"
print("\nTesting Stream Complete:\n")
response = portkey_client.stream_complete(prompt)
for i in response:
print(i.delta, end="", flush=True)
# Let's prepare a set of chat messages and then utilize the stream_chat function to achieve a streamed chat response.
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What can you do?"),
]
print("\nTesting Stream Chat:\n")
response = portkey_client.stream_chat(messages)
for i in response:
print(i.delta, end="", flush=True)
🔍 回顾与参考¶
恭喜!🎉 您已成功设置和测试了 Portkey 与 Llamaindex 的集成。步骤回顾
- pip install portkey-ai
- from llama_index.llms import Portkey
- 从 此处 获取您的 Portkey API Key 并创建您的虚拟提供商密钥。
- 构建您的 Portkey 客户端并设置模式:
portkey_client=Portkey(mode="fallback") - 使用 LLMOptions 构建您的提供商 LLM:
openai_llm = pk.LLMOptions(provider="openai", model="gpt-4", virtual_key=openai_key_a) - 使用
portkey_client.add_llms(openai_llm)将 LLM 添加到 Portkey - 像调用其他任何 LLM 一样,正常调用 Portkey 方法:
portkey_client.chat(messages)
以下是所有函数及其参数的指南
🔁 使用 Portkey 实现回退和重试¶
回退和重试对于构建弹性 AI 应用程序至关重要。使用 Portkey,实现这些功能非常简单
- 回退:如果主要服务或模型失败,Portkey 将自动切换到备用模型。
- 重试:如果请求失败,可以配置 Portkey 多次重试请求。
下面,我们演示如何使用 Portkey 设置回退和重试
portkey_client = Portkey(mode="fallback")
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What can you do?"),
]
llm1 = pk.LLMOptions(
provider="openai",
model="gpt-4",
retry_settings={"on_status_codes": [429, 500], "attempts": 2},
virtual_key=openai_virtual_key_a,
)
llm2 = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_b,
)
portkey_client.add_llms(llm_params=[llm1, llm2])
print("Testing Fallback & Retry functionality:")
response = portkey_client.chat(messages)
print(response)
⚖️ 使用 Portkey 实现负载均衡¶
负载均衡确保将传入请求高效地分配给多个模型。这不仅提高了性能,还提供了冗余,以防某个模型失败。
使用 Portkey,实现负载均衡很简单。您需要
- 定义每个 LLM 的
weight参数。此权重决定了请求在 LLM 之间的分配方式。 - 确保所有 LLM 的权重总和等于 1。
以下是使用 Portkey 设置负载均衡的示例
portkey_client = Portkey(mode="ab_test")
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What can you do?"),
]
llm1 = pk.LLMOptions(
provider="openai",
model="gpt-4",
virtual_key=openai_virtual_key_a,
weight=0.2,
)
llm2 = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_a,
weight=0.8,
)
portkey_client.add_llms(llm_params=[llm1, llm2])
print("Testing Loadbalance functionality:")
response = portkey_client.chat(messages)
print(response)
🧠 使用 Portkey 实现语义缓存¶
语义缓存是一种智能缓存机制,它理解请求的上下文。语义缓存不是仅基于精确输入匹配进行缓存,而是识别相似请求并提供缓存结果,从而减少冗余请求、缩短响应时间并节省成本。
让我们看看如何使用 Portkey 实现语义缓存
import time
portkey_client = Portkey(mode="single")
openai_llm = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_a,
cache_status="semantic",
)
portkey_client.add_llms(openai_llm)
current_messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What are the ingredients of a pizza?"),
]
print("Testing Portkey Semantic Cache:")
start = time.time()
response = portkey_client.chat(current_messages)
end = time.time() - start
print(response)
print(f"{'-'*50}\nServed in {end} seconds.\n{'-'*50}")
new_messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="Ingredients of pizza"),
]
print("Testing Portkey Semantic Cache:")
start = time.time()
response = portkey_client.chat(new_messages)
end = time.time() - start
print(response)
print(f"{'-'*50}\nServed in {end} seconds.\n{'-'*50}")
Portkey 的缓存还支持另外两个对缓存至关重要的功能 - 强制刷新和有效期。
cache_force_refresh:强制向您的提供商发送请求,而不是从缓存中提供。cache_age:决定此特定字符串的缓存存储应自动刷新的时间间隔。缓存有效期以秒为单位。
以下是如何使用它的方法
# Setting the cache status as `semantic` and cache_age as 60s.
openai_llm = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_a,
cache_force_refresh=True,
cache_age=60,
)
🔬 使用 Portkey 实现可观测性¶
了解应用程序的行为至关重要。Portkey 的可观测性功能使您可以轻松监控、调试和优化您的 AI 应用程序。您可以跟踪每个请求,了解其流程,并根据自定义标签对其进行分段。这种详细程度有助于识别瓶颈、优化成本并提升整体用户体验。
以下是如何使用 Portkey 设置可观测性的方法
metadata = {
"_environment": "production",
"_prompt": "test",
"_user": "user",
"_organisation": "acme",
}
trace_id = "llamaindex_portkey"
portkey_client = Portkey(mode="single")
openai_llm = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_a,
metadata=metadata,
trace_id=trace_id,
)
portkey_client.add_llms(openai_llm)
print("Testing Observability functionality:")
response = portkey_client.chat(messages)
print(response)
🌉 开源 AI 网关¶
Portkey 的 AI 网关内部使用了 开源项目 Rubeus。Rubeus 为 LLM 的互操作性、负载均衡、回退等功能提供支持,并充当中间人,确保您的请求得到最优处理。
使用 Portkey 的优点之一是其灵活性。您可以轻松自定义其行为,将请求重定向到不同的提供商,甚至完全绕过向 Portkey 的日志记录。
以下是如何使用 Portkey 自定义行为的示例
portkey_client.base_url=None
📝 使用 Portkey 提供反馈¶
持续改进是 AI 的基石。为了确保您的模型和应用程序不断发展并更好地服务用户,反馈至关重要。Portkey 的 Feedback API 提供了一种直接的方式来收集用户的加权反馈,使您能够随着时间的推移进行改进。
以下是如何使用 Portkey 的 Feedback API
import requests
import json
# Endpoint URL
url = "https://api.portkey.ai/v1/feedback"
# Headers
headers = {
"x-portkey-api-key": os.environ.get("PORTKEY_API_KEY"),
"Content-Type": "application/json",
}
# Data
data = {"trace_id": "llamaindex_portkey", "value": 1}
# Making the request
response = requests.post(url, headers=headers, data=json.dumps(data))
# Print the response
print(response.text)
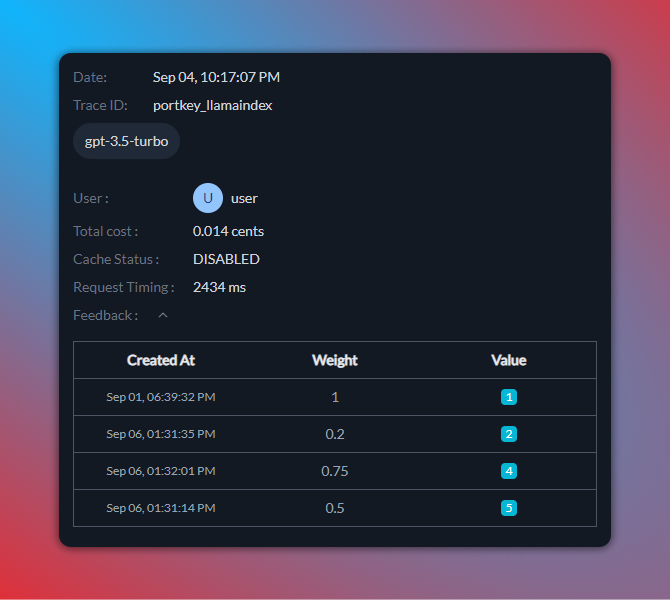
每个 trace id 带有 weight 和 value 的所有反馈都可在 Portkey 控制面板上查看
✅ 结论¶
将 Portkey 与 Llamaindex 集成简化了构建强大且弹性的 AI 应用程序的过程。借助语义缓存、可观测性、负载均衡、反馈和回退等功能,您可以确保最佳性能和持续改进。
通过遵循本指南,您已设置并测试了 Portkey 与 Llamaindex 的集成。在您继续构建和部署 AI 应用程序时,请记住充分利用此集成的潜力!
如需进一步帮助或有疑问,请联系开发者 ➡️

加入我们将 LLM 投入生产的从业者社区 ➡️
