![]()
使用 VideoDB 的多模态 RAG¶
RAG:视频多模态搜索和流式视频结果 📺¶
构建文本 RAG 管道相对简单,这得益于为解析、索引和检索文本数据而开发的工具。
然而,将 RAG 模型用于视频内容提出了更大的挑战。视频结合了视觉、听觉和文本元素,需要更多的处理能力和复杂的视频管道。
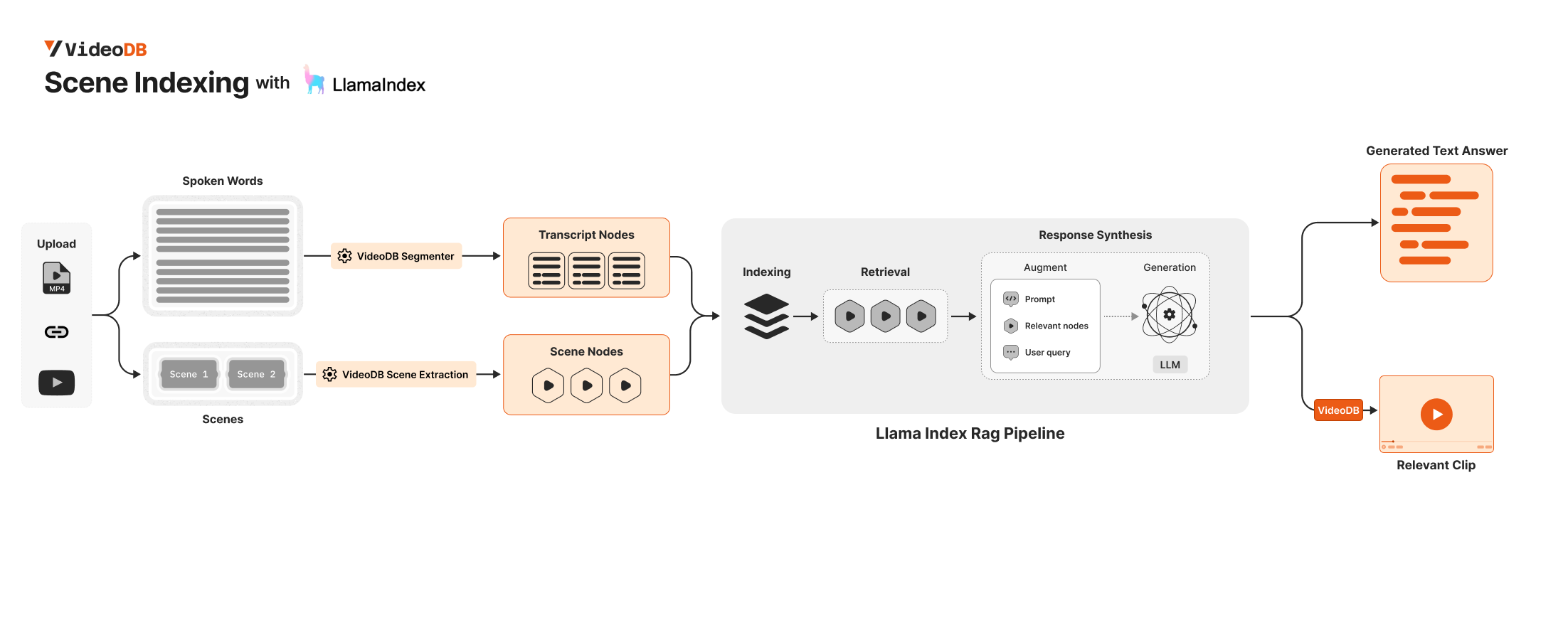
VideoDB 是一个无服务器数据库,旨在简化视频内容的存储、搜索、编辑和流式传输。VideoDB 通过构建索引并开发用于查询和浏览视频内容的接口,提供对顺序视频数据的随机访问。在 docs.videodb.io 了解更多信息。
为了构建真正用于视频的多模态搜索,您需要处理视频的不同模态,例如语音内容、视觉内容。
在本 Notebook 中,我们将使用 VideoDB 和 Llama-Index ✨ 开发一个用于视频的多模态 RAG。
🔑 要求¶
要连接到 VideoDB,只需获取 API 密钥并创建连接即可。这可以通过设置 VIDEO_DB_API_KEY 环境变量来实现。您可以从 👉🏼 VideoDB Console 获取它。(前 50 次上传免费,无需信用卡!)
从 OpenAI 平台获取您的 OPENAI_API_KEY,用于 llama_index 响应合成器。
import os
os.environ["VIDEO_DB_API_KEY"] = ""
os.environ["OPENAI_API_KEY"] = ""
%pip install videodb
%pip install llama-index
🛠 构建多模态 RAG¶
from videodb import connect
# connect to VideoDB
conn = connect()
coll = conn.get_collection()
# upload videos to default collection in VideoDB
print("Uploading Video")
video = conn.upload(url="https://www.youtube.com/watch?v=libKVRa01L8")
print(f"Video uploaded with ID: {video.id}")
# video = coll.get_video("m-56f55058-62b6-49c4-bbdc-43c0badf4c0b")
Uploading Video Video uploaded with ID: m-0ccadfc8-bc8c-4183-b83a-543946460e2a
coll = conn.get_collection(): 返回默认集合对象。coll.get_videos(): 返回集合中所有视频的列表。coll.get_video(video_id): 从给定的video_id返回 Video 对象。
📸🗣️ 步骤 2:从视频中提取场景¶
首先,我们需要从视频中提取场景,然后使用 vLLM 获取每个场景的描述。
要了解有关场景提取选项的更多信息,请查阅以下指南
- 场景提取选项指南 深入探讨了 Scene Index 中可用的各种场景提取选项。它涵盖了高级设置、自定义功能以及根据不同需求和偏好优化场景提取的技巧。
from videodb import SceneExtractionType
# Specify Scene Extraction algorithm
index_id = video.index_scenes(
extraction_type=SceneExtractionType.time_based,
extraction_config={"time": 2, "select_frames": ["first", "last"]},
prompt="Describe the scene in detail",
)
video.get_scene_index(index_id)
print(f"Scene Extraction successful with ID: {index_id}")
Indexing Visual content in Video... Scene Index successful with ID: f3eef7aee2a0ff58
✨ 步骤 3:将 VideoDB 集成到现有的 Llamaindex RAG 管道中¶
为了开发全面的视频多模态搜索,您需要处理不同的视频模态,包括语音内容和视觉元素。
您可以使用 VideoDB 检索视频的所有转录节点和视觉节点,然后将其集成到您的 LlamaIndex 管道中。
🗣 获取转录节点¶
您可以使用 Video.get_transcript() 获取转录节点
要配置分割器,请使用 segmenter 和 length 参数。
segmenter 可能的值为
Segmenter.time: 根据指定的length(秒) 分割视频。Segmenter.word: 根据length指定的字数分割视频
from videodb import Segmenter
from llama_index.core.schema import TextNode
# Fetch all Transcript Nodes
nodes_transcript_raw = video.get_transcript(
segmenter=Segmenter.time, length=60
)
# Convert the raw transcript nodes to TextNode objects
nodes_transcript = [
TextNode(
text=node["text"],
metadata={key: value for key, value in node.items() if key != "text"},
)
for node in nodes_transcript_raw
]
📸 获取场景节点¶
# Fetch all Scenes
scenes = video.get_scene_index(index_id)
# Convert the scenes to TextNode objects
nodes_scenes = [
TextNode(
text=node["description"],
metadata={
key: value for key, value in node.items() if key != "description"
},
)
for node in scenes
]
🔄 带有转录 + 场景节点的简单 RAG 管道¶
我们索引转录节点和场景节点
🔍✨ 为了简单起见,我们使用了基本的 RAG 管道。但是,您可以在此处集成更高级的 LlamaIndex RAG 管道以获得更好的结果。
from llama_index.core import VectorStoreIndex
# Index both Transcript and Scene Nodes
index = VectorStoreIndex(nodes_scenes + nodes_transcript)
q = index.as_query_engine()
The narrator discusses the location of our Solar System within the Milky Way galaxy, emphasizing its position in one of the minor spiral arms known as the Orion Spur. The images provided offer visual representations of the Milky Way's structure, with labels indicating the specific location of the Solar System within the galaxy.
️💬️ 查看结果:文本¶
res = q.query(
"Show me where the narrator discusses the formation of the solar system and visualize the milky way galaxy"
)
print(res)
🎥 查看结果:视频剪辑¶
我们的节点元数据包含 start 和 end 字段,它们表示相对于视频开头的开始时间和结束时间。
利用相关节点中的这些信息,我们可以创建对应于这些节点的视频剪辑。
from videodb import play_stream
# Helper function to merge overlapping intervals
def merge_intervals(intervals):
if not intervals:
return []
intervals.sort(key=lambda x: x[0])
merged = [intervals[0]]
for interval in intervals[1:]:
if interval[0] <= merged[-1][1]:
merged[-1][1] = max(merged[-1][1], interval[1])
else:
merged.append(interval)
return merged
# Extract relevant timestamps from the source nodes
relevant_timestamps = [
[node.metadata["start"], node.metadata["end"]] for node in res.source_nodes
]
# Create a compilation of all relevant timestamps
stream_url = video.generate_stream(merge_intervals(relevant_timestamps))
play_stream(stream_url)